
Cientistas de dados e empresas criam modelos de machine learning a todo momento para os mais diversos tipos de tarefas. Ao se deparar com a necessidade de usar um modelo para classificação de textos ou geração de imagens, por exemplo, é possível começar de um ponto de partida mais avançado ou até consumir um modelo que esteja 100% alinhado com o que você precisa.
Além dos artigos dos pesquisadores que contribuíram para a construção desses modelos, uma ótima fonte para encontrá-los é a plataforma Hugging Face. Ela conta com uma interface amigável e diversos filtros, como a atividade-fim do modelo:
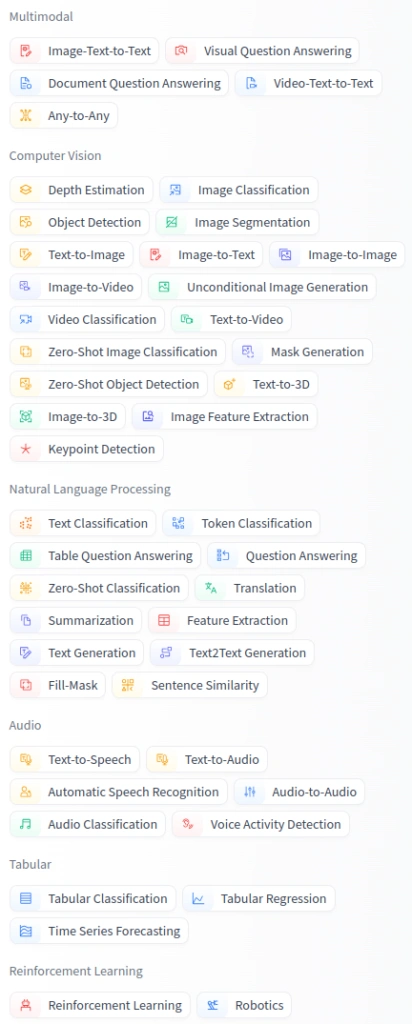
Para demonstrar a aplicabilidade da Hugging Face, utilizarei um modelo de classificação de sentimentos para analisar comentários de compras do dataset da Olist. Esse conjunto de dados contém avaliações dos consumidores, e o modelo identifica automaticamente se o sentimento dos comentários é positivo, neutro ou negativo.
Exemplo prático: classificação de sentimentos em comentários
Como o dataset possui comentários em português, utilizarei o modelo pysentimiento/bertweet-pt-sentiment. Para utilizá-lo, é necessário instalar as bibliotecas transformers e PyTorch:
pip install transformers torchApós importar as bibliotecas necessárias, a referência e o download do modelo são feitos usando a classe pipeline da biblioteca transformers.
import numpy as np
import pandas as pd
from pathlib import Path
from pprint import pprint
from transformers import pipeline
modelo_sentimento = pipeline(
task="sentiment-analysis",
model="pysentimiento/bertweet-pt-sentiment"
)Para testar se o modelo foi carregado corretamente, basta passar um texto diretamente da célula do seu notebook e verificar o formato da resposta.
resposta_modelo = modelo_sentimento(
"gostei bastante do produto recebido",
top_k=None
)
pprint(resposta_modelo)
Além de trazer o sentimento do texto, o modelo retorna também o score de cada uma das categorias, o que pode ser útil ao lidar com casos mais ambíguos.
Agora, vamos carregar o dataset com as notas e comentários das compras feitas pelos clientes.
caminho_arquivo = "/home/henrique/Projetos/olist-brazilian-ecommerce-analysis/data/raw/olist_order_reviews_dataset.csv"
avaliacoes = pd.read_csv(caminho_arquivo)
avaliacoes.head(1).T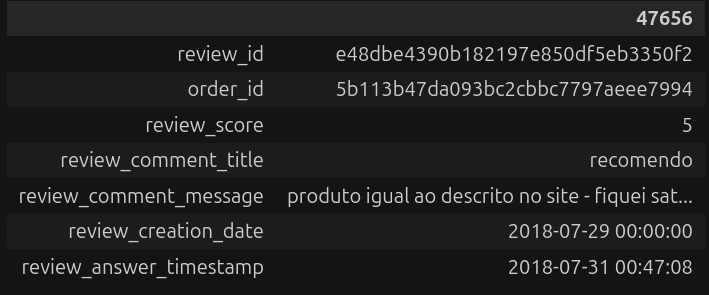
Como há informações úteis tanto no título quanto no corpo do comentário, concatenarei os dois campos e realizarei alguns tratamentos para facilitar a análise de sentimento.
# Concatena o título do comentário com o seu conteúdo
avaliacoes["review_text"] = (
avaliacoes["review_comment_title"].fillna("")
+ " "
+ avaliacoes["review_comment_message"].fillna("")
)
# Converte para letras minúsculas
avaliacoes["review_text"] = avaliacoes["review_text"].str.lower()
# Remove caracteres especiais
avaliacoes["review_text"] = avaliacoes["review_text"].str.replace(
r"[^\w\s]", " ", regex=True
)
# Remove números
avaliacoes["review_text"] = avaliacoes["review_text"].str.replace(
r"\d+", "", regex=True
)
# Remove quebras de linhas
avaliacoes["review_text"] = avaliacoes["review_text"].str.replace(
r"\n", " ", regex=True
)
# Remove espaçamento múltiplo
avaliacoes["review_text"] = avaliacoes["review_text"].str.replace(
r"\s+", " ", regex=True
)
# Remove espaços como primeiro ou último caracteres
avaliacoes["review_text"] = avaliacoes["review_text"].str.strip()
# Substitui strings vazias por NaN
avaliacoes["review_text"] = avaliacoes["review_text"].replace("", np.nan)Com a execução desse código, a nova coluna criada descarta casos onde o comentário é apenas um ponto ou espaço em branco, mantendo aqueles com pelo menos uma palavra. Para dimensionar a proporção de comentários nas avaliações, vamos contar os valores nulos na coluna "review_text".
avaliacoes["review_text"].isna().value_counts()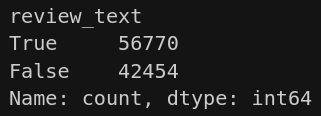
A seguir, selecionarei 1.000 comentários aleatórios da base e as três variáveis "review_id", "review_score" e "review_text".
amostra_comentarios = avaliacoes.loc[
avaliacoes["review_text"].notna(),
["review_id", "review_score", "review_text"]
].sample(1000).copy()Além da lista de dicionários retornada pelo modelo, criarei uma coluna para cada score dos três sentimentos e uma coluna adicional com o sentimento de maior pontuação.
# Cria uma coluna com o dicionário de sentimentos e seus respectivos scores
amostra_comentarios["sentiment"] = amostra_comentarios["review_text"].map(
lambda x: {
dictionary["label"]: dictionary["score"]
for dictionary in modelo_sentimento(x, top_k=None)
},
na_action="ignore",
)
# Separa o sentimento em diferentes colunas
amostra_comentarios["positive_score"] = amostra_comentarios[
"sentiment"
].map(lambda x: x["POS"] if isinstance(x, dict) else np.nan)
amostra_comentarios["neutral_score"] = amostra_comentarios["sentiment"].map(
lambda x: x["NEU"] if isinstance(x, dict) else np.nan
)
amostra_comentarios["negative_score"] = amostra_comentarios[
"sentiment"
].map(lambda x: x["NEG"] if isinstance(x, dict) else np.nan)
# Cria uma coluna com o sentimento de maior score para o comentário
sentiment_labels = {"POS": "Positive", "NEU": "Neutral", "NEG": "Negative"}
amostra_comentarios["sentiment_label"] = amostra_comentarios[
"sentiment"
].map(
lambda x: sentiment_labels.get(max(x, key=x.get))
if isinstance(x, dict)
else np.nan
)
amostra_comentarios.head()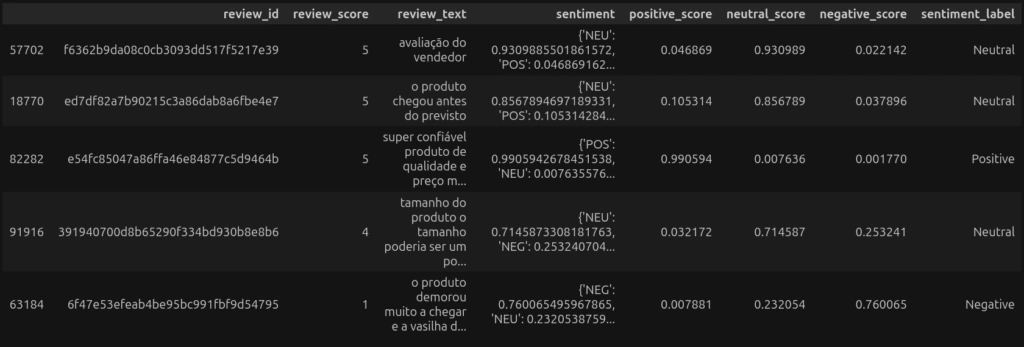
Para verificar se a classificação de sentimento foi adequada, selecionarei aleatoriamente 5 comentários e suas notas, começando pelos positivos.
# Positivos
print(
amostra_comentarios
.loc[amostra_comentarios["sentiment_label"] == "Positive", ["review_score", "review_text", "positive_score"]]
.sample(5)
.to_markdown()
)
A classificação feita pelo modelo concorda tanto com o texto escrito quanto com a nota dada pelo cliente, sem grandes insights.
# Neutros
print(
amostra_comentarios
.loc[amostra_comentarios["sentiment_label"] == "Neutral", ["review_score", "review_text", "neutral_score"]]
.sample(5)
.to_markdown()
)
Nos comentários classificados como "neutros", há notas nos dois extremos. As notas máximas trazem dois comentários indicando que o produto foi entregue normalmente, enquanto o terceiro diz que o produto veio com defeito, mas a loja irá realizar a troca. Já nas notas mínimas, em um deles o próprio cliente diz que o produto está no prazo de entrega, mas avaliou com 1 estrela; no outro, o cliente informa que a entrega foi feita parcialmente, com a falta de um dos produtos.
# Negativos
print(
amostra_comentarios
.loc[amostra_comentarios["sentiment_label"] == "Negative", ["review_score", "review_text", "negative_score"]]
.sample(5)
.to_markdown()
)
Por fim, nos comentários classificados como "negativos", há notas neutras e detratoras com comentários sobre: produtos não entregues (ou entregues depois do prazo), produto diferente do divulgado no site e cobrança de frete individual para produtos repetidos.
Outro uso para o modelo é entender casos onde o sentimento é positivo mas a nota é detratora, ou o sentimento é negativo mas a nota é promotora. A seguir, uma amostra de 5 comentários nessas situações.
# Notas divergentes do sentimento
print(
amostra_comentarios
.loc[
((amostra_comentarios["sentiment_label"] == "Positive") & (amostra_comentarios["review_score"].isin([1, 2])))
|
((amostra_comentarios["sentiment_label"] == "Negative") & (amostra_comentarios["review_score"].isin([4, 5]))),
["review_score", "review_text", "sentiment_label"],
]
.sample(5)
.to_markdown()
)
O segundo e terceiro comentários da amostra mostram que, apesar do cliente elogiar a plataforma e o produto recebido, ele deu uma nota baixa. Uma ação possível seria desconsiderar essas avaliações na composição das métricas das lojas, já que não houve nenhum problema. O primeiro e o último comentários trazem reclamações sobre preço e prazo do frete, mas com notas boas — o que indica que o produto não era urgente para o último caso, enquanto o primeiro sugere um produto de baixo valor com vendedor distante do comprador. Já o quarto comentário relata o atraso de um dos produtos da compra, mas com nota boa porque o outro produto chegou antes do prazo.
Se você já tem contato com Python, o uso de modelos pré-treinados é relativamente simples com a Hugging Face. Cada modelo pode usar bibliotecas diferentes e ter formas distintas de ser utilizado, sendo sempre necessário consultar o código de exemplo na aba "Model card".
Para dúvidas específicas de um modelo, é possível abrir uma discussão na aba "Community" do próprio modelo. Para dúvidas mais genéricas, o fórum do Hugging Face é uma boa opção para interagir com a comunidade.