A Olist é uma empresa brasileira de tecnologia fundada em 2015 que oferece soluções de gestão de e-commerce e disponibilização de produtos de lojistas em diferentes marketplaces. Em 2018, a empresa disponibilizou no Kaggle uma base de dados anonimizada com uma amostra das vendas ocorridas desde o final de 2016 até agosto de 2018, possibilitando diversos tipos de análises.
Neste artigo, farei uma análise exploratória de dados (EDA) usando as informações disponibilizadas pela empresa, incluindo a análise de sentimento dos comentários deixados pelos clientes.
Todo o código usado neste artigo foi disponibilizado no meu GitHub no repositório olist-brazilian-ecommerce-analysis (em inglês).
Modelagem dos dados
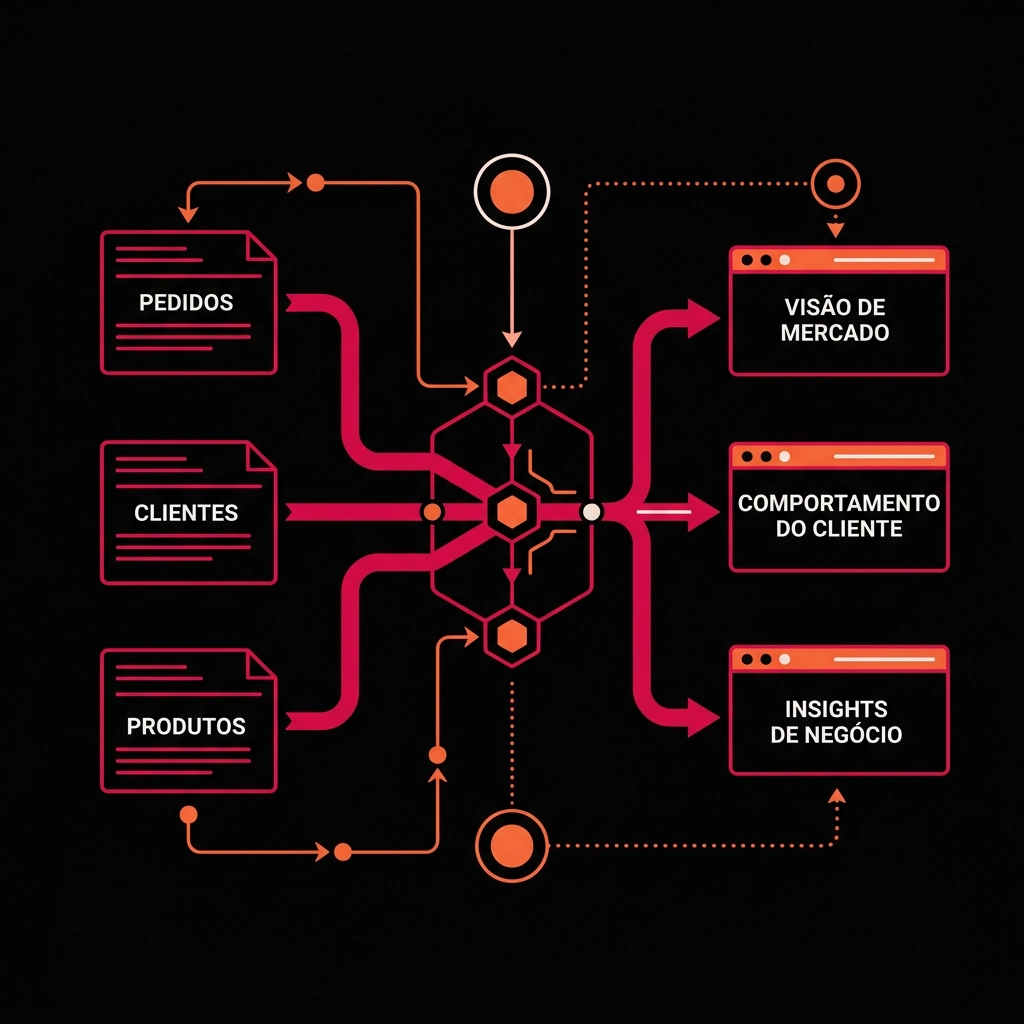
O primeiro passo da análise é entender o relacionamento entre os diferentes arquivos de dados disponibilizados pela Olist. Essa etapa garante o cruzamento correto das bases ao longo da análise.
Com o auxílio da ferramenta online dbdiagram, mapeei as 9 tabelas disponibilizadas no Kaggle com os nomes dos campos e seus respectivos tipos de dados.

Sobre a forma como os dados foram disponibilizados, dois pontos são importantes para os cruzamentos feitos ao longo da análise:
- Na tabela "olist_customers", temos os atributos "customer_id" e "customer_unique_id" que parecem ambíguos em um primeiro momento, mas a explicação é que um usuário possui um único "customer_unique_id" e, a cada compra feita, é gerado um novo "customer_id";
- Já na tabela "olist_geolocation", não existe uma chave primária pelo CEP (chamado de "zip_code_prefix"). Como o CEP é truncado mantendo apenas os 5 primeiros dígitos, existem repetições na base que levam a diferentes valores de latitude e longitude. Mais adiante veremos como lidar com esse caso.
Análise exploratória de dados
Quantidade de compras e valores totais pagos por estado e status da compra
Será que os dados disponibilizados pela Olist mostram concentração de valores monetários em algum estado ou região específica do Brasil? Esse comportamento é o mesmo para a quantidade de compras feitas?
Para responder a essa pergunta, o gráfico a seguir mostra o valor total dos pagamentos e a contagem de compras distintas por estado e status do pedido.
O gráfico mostra que tanto os três maiores valores totais pagos quanto a quantidade total de pedidos são de estados da região sudeste do Brasil: São Paulo (SP), Rio de Janeiro (RJ) e Minas Gerais (MG).
Origem e destino das compras por região do Brasil
A análise anterior foca apenas no cliente. Mas qual é a região responsável pela maior parte da origem dos produtos? Existe concentração no destino a depender da região do vendedor? O gráfico de Sankey a seguir contabiliza a quantidade de vendas agrupando pela região do vendedor e pela região do cliente.
Além do sudeste ser a região dos clientes com a maior quantidade de pedidos, ela é responsável também pelo suprimento de quase todos os pedidos feitos por clientes das outras regiões. Podemos destacar também a participação da região sul como 2ª região principal no fornecimento de produtos para o sudeste, destoando das regiões nordeste, centro-oeste e norte.
Distribuição espacial dos clientes e vendedores
Os gráficos anteriores consideravam a quantidade de vendas ou o valor total pago pelo cliente, mas como se distribuem os clientes e vendedores (distintos) pelo país? Para obter a localização aproximada, foi calculada a média da latitude e da longitude agrupada pelo atributo "geolocation_zip_code_prefix" da tabela "olist_geolocation". Com isso, existe apenas uma coordenada geográfica para cada prefixo de CEP, sendo possível relacioná-la tanto com os clientes quanto com os vendedores.
Os mapas de densidade a seguir mostram essas distribuições:
Os dois mapas de densidade confirmam a concentração tanto de clientes quanto de vendedores na região sudeste. Essa concentração é ainda mais acentuada entre os vendedores.
Tendência de vendas pelas principais categorias de produtos
Com um histórico de quase 2 anos de dados amostrais de vendas, é possível observar a tendência de vendas por categoria de produto.
Com exceção de categorias menos significativas que foram agrupadas em "outros", a categoria de artigos para a casa lidera a quantidade total de compras feitas na base de dados, mostrando um pico no mês de nov/2017 (onde ocorre a Black Friday).
É possível perceber também uma tendência no aumento da quantidade total de vendas ao longo de 2017 com uma estabilização nos meses de 2018. Lembrando que esses dados podem não representar a realidade dos marketplaces devido ao processo de amostragem dos dados disponibilizados.
Métricas de clientes
A seguir, exploraremos algumas métricas calculadas para os clientes PF do varejo.
Recência
A recência pode ser definida como a quantidade de dias passados desde a última compra feita por um cliente.
Devido ao comportamento anômalo dos dados dos últimos meses da base "olist_orders", foram filtradas apenas as compras feitas até o mês de ago/2018 e a recência foi calculada com base na data de 31/08/2018. A seguir, o histograma mostra a quantidade de clientes pela quantidade de dias desde o seu último pedido.
Os clientes situados na área azul do gráfico são aqueles que fizeram sua última compra há menos de 180 dias, enquanto os clientes na região vermelha fizeram sua última compra 180 dias atrás ou antes. A amostra indica que os clientes tendem a se cadastrar para uma compra pontual, sem manter um hábito de compra frequente na plataforma.
Outro ponto importante de se observar é que o maior pico de clientes, com recência entre 275 e 284 dias, fez sua última compra na semana da Black Friday de 2017, no ano anterior à data de referência. Por se tratar de uma quantidade significativa da base de clientes da plataforma, que agora estão inativos, seria interessante fazer alguma ação de marketing focada nesse público para reativá-los.
Churn
Como vimos no histograma de recência anteriormente, a maior parte dos clientes da base se encontra "inativa", ou seja, não realizou uma compra nos últimos X dias. Aqui definimos essa quantidade X como 180 dias (ou seja, quase 6 meses).
Calculando a proporção de clientes em cada uma das situações, vemos que apenas 39,9% dos clientes (38.309) encontram-se "ativos" na plataforma, enquanto os 61,1% demais (57.781) não fizeram nenhuma compra nesse período.
Frequência
Com quase 100 mil pedidos registrados nas bases, como eles se distribuem pela quantidade de clientes? A frequência de cada cliente é simplesmente a contagem de pedidos feitos por ele. O histograma abaixo mostra essa distribuição.
Do gráfico anterior, quase 97% dos clientes fizeram uma única compra na plataforma em todo o período analisado, reforçando que o processo de amostragem pode não representar fielmente a base de clientes da Olist.
Receita total
A receita total do cliente é o total pago por ele em todas as suas compras na plataforma. Como a frequência por cliente é baixa, é esperado que a receita total também não seja elevada. A seguir, a distribuição da contagem de clientes únicos pela receita total.
Essa distribuição altamente assimétrica mostra uma concentração de receita total por cliente em valores mais baixos, geralmente de até R$ 200,00. Para visualizar melhor essa proporção, plotaremos um gráfico de distribuição de frequência acumulada.
Do gráfico anterior é possível confirmar que 78% dos clientes possuem uma receita total acumulada de até R$ 200. Além disso, receitas totais acima de R$ 915,00 representam menos de 1% dos clientes.
Análise dos comentários
O dataset possui informações de quase 100 mil compras, mas qual é o volume de comentários disponível para análise? O cliente pode não deixar uma avaliação ou deixar apenas a nota de 1 a 5 estrelas, sem comentário. O gráfico de waterfall abaixo mostra o comportamento de avaliação dos clientes.
Do gráfico anterior, praticamente todas as compras possuem a avaliação em estrelas feita pelos clientes. Entretanto, mais da metade das compras não possui nenhum comentário, reduzindo a quantidade total para quase 41 mil comentários. Apesar de ser impossível avaliá-los de forma manual, esse volume ainda permite extrair insights usando um modelo de classificação de sentimentos.
O passo a passo mais detalhado de como utilizar um modelo pré-treinado da plataforma Hugging Face pode ser encontrado no meu último artigo Modelos pré-treinados para tarefas de ciência de dados, onde mostro como instalar as bibliotecas necessárias e baixar o modelo para essa situação.
Após a aplicação do modelo pysentimiento/bertweet-pt-sentiment na base de comentários, cada um deles foi classificado em "negativo", "neutro" e "positivo". Como se dá a distribuição desses sentimentos em relação à nota dada pelo cliente?
Algumas informações interessantes podem ser extraídas desse gráfico. A primeira é que a proporção de avaliações sem comentários é inversamente proporcional à nota dada pelo cliente. Ou seja, clientes muito satisfeitos tendem a deixar menos comentários do que aqueles que tiveram algum problema e deram notas baixas.
Em segundo lugar, como esperado, a proporção de comentários positivos é proporcional à nota, enquanto os comentários negativos são inversamente proporcionais à nota.
Essa análise exploratória de dados permitiu conhecer um pouco mais sobre o dataset da Olist e o comportamento dos clientes no período disponibilizado. Por não ser uma análise exaustiva, outros pontos podem ser explorados, tais como:
- Atrasos nas entregas
- Leva a uma quantidade maior de notas baixas e quantidade nas entregas?
- Quais tipos de produtos possuem uma proporção maior de atrasos?
- Em quais regiões (tanto do vendedor quanto do cliente) isso ocorre?
- Valor do frete
- O quanto ele representa do total pago pelo cliente no pedido?
- Pedidos similares (produto, dimensões, distância entre cliente e vendedor) com preços de frete diferentes levam a tempos de entrega diferentes?
- Métodos de pagamento
- Quais formas de pagamento são mais presentes nas compras da plataforma?
- As compras geralmente são parceladas? Isso varia de acordo com o valor pago?
- Qual é o comportamento (categoria de produtos, % de desconto, tipos de clientes) no uso de cupons de desconto?
E você, já analisou esse dataset alguma vez? Quais informações conseguiu extrair dos dados?